Claude Code と Cloudflare Workers AI で5種類のAIを動かすデモサイトを作る
⚠️ 現在製作中のため、内容は不正確なことがあります。
自分の API キーも GPU も用意せず、Cloudflare の上で AI モデルを動かす。それが Cloudflare Workers AI。本記事では 翻訳・要約/カテゴリ分類/画像キャプション生成/画像生成/音声書き起こし という毛色の違う5つの AI を、1つの Worker にまとめて「AI デモサイト」を作る。
題材は5つだが、やることはどれも同じ。env.AI.run("モデル名", 入力) を呼ぶだけ。認証もサーバー構築も要らず、無料枠の範囲で一通り動かせる。
本記事は応用編。ロードマップの Wranglerハンズオン を完了している前提で進める。Wrangler で手元から直接デプロイする方式なので、GitHub も Git連携も不要。
本記事の位置付け
Section titled “本記事の位置付け”「AI を使ったサービスを作ってみたい」と思ったとき、まず思い浮かぶのは OpenAI や Claude の API かもしれない。ただしそれらは API キーの発行・課金設定・キーの秘匿管理が必要で、最初の一歩としてはハードルが高い。
Cloudflare Workers AI なら、Worker に AI バインディング を1行足すだけで、キーの管理なしに AI を呼べる。品質は Claude や GPT の上位モデルには遠く及ばないが、「翻訳」「要約」「画像の説明」「画像生成」「文字起こし」くらいの用途なら場合によっては十分実用になる。
本記事では、その Workers AI を 触って感触をつかむ ことをゴールにする。5つのデモを1つずつ作り、実装するたびにデプロイして公開サイトで動作を確かめながら 進める。
1. 何を作るか
Section titled “1. 何を作るか”1ページに5つのタブを並べ、それぞれが別の AI モデルを呼ぶデモサイト。
| タブ | やること | 使うモデル |
|---|---|---|
| 翻訳・要約 | テキストを日本語⇄英語に翻訳、長文を要約 | Llama 3.1 8B |
| カテゴリ分類 | 問い合わせ文を内容でカテゴリに振り分け(埋め込み) | PLaMo Embedding |
| 画像キャプション | アップした画像に何が写っているか説明 | Llama 4 Scout(マルチモーダル) |
| 画像生成 | テキストから画像を生成してダウンロード | FLUX.1 [schnell] |
| 音声書き起こし | 音声ファイルを文字起こし | Whisper |
全体像。フロントエンド(public/)は静的ファイルとして配信し、/api/* へのリクエストだけ Worker が処理して Workers AI を呼ぶ。
sequenceDiagram
participant pg as ブラウザ(5タブUI)<br>=フロントエンド
participant wk as Worker(/api/*)<br>=バックエンド
participant ai as Workers AI<br>(各モデル)
pg->>wk: 静的ファイル(index.html / app.js / style.css)を要求
wk-->>pg: Static Assets を配信
pg->>wk: fetch POST /api/translate など(入力データ)
wk->>ai: env.AI.run("@cf/...", 入力)
ai-->>wk: 推論結果
wk-->>pg: JSON で返す
Note over pg: 結果を画面に表示
構成はシンプル。public/ に置いた HTML/JS/CSS がそのまま配信され、API だけ Worker が引き受ける。
2. Cloudflare Workers AI とは
Section titled “2. Cloudflare Workers AI とは”Cloudflare のグローバルな GPU 上で、オープンモデル(Llama、Flux、Whisper など)を サーバーレス で動かせるサービス。自分で GPU を借りる必要も、モデルをダウンロードする必要もない。Worker から env.AI.run() を呼ぶだけで AI に処理を任せられる。
2-1. どんなモデルがあるか
Section titled “2-1. どんなモデルがあるか”Workers AI には50以上のモデルがあり、用途ごとに使い分ける。代表的なもの:
| カテゴリ | 代表モデル | 本記事で使う |
|---|---|---|
| テキスト生成(翻訳・要約・チャット) | Llama 3.1 8B / 3.3 70B、Mistral、GPT-OSS など | Llama 3.1 8B |
| マルチモーダル(画像+テキスト) | Llama 4 Scout、Llama 3.2 Vision | Llama 4 Scout |
| 画像生成 | FLUX、Stable Diffusion | FLUX.1 [schnell] |
| 音声認識(文字起こし) | Whisper | Whisper large v3 turbo |
| 埋め込み(分類・RAG用) | BGE、PLaMo(日本語特化) | PLaMo-Embedding-1B |
本記事ではこのうち5カテゴリを1つずつ触る。同じ env.AI.run() でモデル名を差し替えるだけで、まったく毛色の違う AI に切り替わるのが Workers AI の手軽さ。
モデルの全一覧は公式の Workers AI Models カタログ で見られる。各モデルのページにモデルID(
@cf/...)・入出力・コード例・料金が載っている。Cloudflare ダッシュボードの Workers & Pages → AI → Models からも一覧できる。
2-2. 料金(無料枠)
Section titled “2-2. 料金(無料枠)”- 無料枠: 1日あたり 10,000 Neurons(毎日 00:00 UTC=日本時間9時にリセット)
- 超過分: $0.011 / 1,000 Neurons(1ドル150円なら約1.65円)
Neuron は Workers AI の利用量を測る単位。モデルや入出力の量に応じて消費される。
分量の目安:
| 用途 | 1回あたりの目安 | 無料枠(1万 N)でできる回数 |
|---|---|---|
| Llama 3.1 8B で短文を翻訳・要約 | 約 2〜5 N | 約 2,000〜4,000 回 |
| PLaMo Embedding でカテゴリ分類 | 約 1 N 未満 | 約 1 万回以上 |
| Llama 4 Scout で画像のキャプションを生成(小さめの画像) | 約 14 N | 約 700 回 |
| FLUX.1 [schnell] で 1024×1024 の画像を生成(4ステップ) | 約 170 N | 約 58 枚 |
| Whisper large v3 turbo で音声を文字起こし | 約 47 N/分 | 約 210 分 |
上の「1回あたり」の数値は推測ではなく、2026年6月12日に各モデルへ実際にテスト送信し、Cloudflare ダッシュボードの消費量から逆算した実測値(固定入力を既知の回数だけ呼び、差分を割って算出)。ただし料金体系は変わることがあるので、正確な現在値は自分のダッシュボードで確認するとよい。なお、カテゴリ分類(埋め込み)は非常に軽く、ダッシュボードの実使用では長めの文を含めても1回あたり 0.1 N 未満(十数回の分類でも合計 1 N 程度)だった。生成系(テキスト・画像・音声)に比べて埋め込みのコストは桁違いに小さい。
実際の消費は入出力の長さやステップ数で変わる。テキスト系(翻訳・要約・キャプション)は数 N と安いが、とくに 画像生成は1枚あたり約170 N(テキスト処理の数十倍)と重く、無料枠が一気に減る(ステップ数を増やすとさらに増える)。正確な消費量は Cloudflare ダッシュボードの Workers & Pages → AI で確認できる。実際、このデモを作る中で消費した Neuron の9割以上が画像生成だった。
Cloudflare は将来、課金単位を Neuron からモデル別・トークン別の表示へ整理していく方針を示している。現時点では Neuron 単位が有効だが、本格運用する前に 公式の料金ページ を確認するとよい。
2-3. 無料枠を超えたらどうなるか
Section titled “2-3. 無料枠を超えたらどうなるか”「うっかり使いすぎて高額請求が来ないか」が気になるところ。挙動はプランで変わる。
| プラン | 無料枠を超えると |
|---|---|
| Workers Free(無料のまま) | その日のリクエストが エラーで止まる。課金はされない。00:00 UTC(日本時間 朝9時)にリセットされ、翌日また無料枠が復活する |
| Workers Paid(月 $5 のサブスク) | 超過分が 自動的に従量課金($0.011 / 1,000 Neurons)。超過を止めるハードな上限スイッチはない |
無料プランのままなら、勝手に課金されることはない。 無料枠を使い切ると「その日は打ち止め、翌日また使える」という動きになる。まず試す段階では Free のままが安心。
逆に Paid プランにすると無料枠を超えた分は自動で課金されるので、本格運用するなら Worker 側にレート制限を入れる・ダッシュボードで使用量を監視する、といった備えをしておくとよい。
個人で試す範囲なら、まず無料枠を超えない。 仮に超えても、無料枠1日分(1万 Neurons)を追加で使って約17円。本記事のデモを一通り触る程度では誤差レベル。
3. 事前準備
Section titled “3. 事前準備”ここからは実際に手を動かして、Workers AI のデモサイトを作っていく。まずは準備から。
3-1. 作業フォルダを作って Claude Code を起動
Section titled “3-1. 作業フォルダを作って Claude Code を起動”作業フォルダ ~/Desktop/claude/workers-ai-demo を作って、Claudeデスクトップアプリを起動。
Code(Claude Code)を選択 → New session をクリック → 作業フォルダを指定(~/Desktop/claude/workers-ai-demo)
名前は別のものでもよい。以降
workers-ai-demoと出てきたら自分のプロジェクト名に読み替える。
公開ファイルは public/ 配下、Worker のコードは src/index.js、設定ファイルはルート直下に置く構成にする。
3-2. Wrangler ログイン状態の確認
Section titled “3-2. Wrangler ログイン状態の確認”Wrangler ハンズオンを完了していれば、Node.js と Wrangler ログインは済んでいるはず。下記コマンドで確認する。
npx wrangler whoamiアカウント名やメールアドレスが表示されればOK。表示されない場合は Wranglerハンズオンの2章 を参照してインストール・ログインする。
4. wrangler.jsonc を作る
Section titled “4. wrangler.jsonc を作る”Worker と静的ファイル配信、そして AI バインディングをつなぐ設定ファイル。Claude Code に作成を依頼する。
以下のテンプレートで wrangler.jsonc をプロジェクトのルートに作成してください。プロジェクト名は「workers-ai-demo」、YYYY-MM-DD は昨日の日付にしてください。
{ "name": "プロジェクト名", "main": "src/index.js", "compatibility_date": "YYYY-MM-DD", "assets": { "directory": "./public", "binding": "ASSETS" }, "ai": { "binding": "AI" }}各項目の意味:
| 項目 | 内容 |
|---|---|
main | API リクエストを処理する Worker スクリプトのパス |
compatibility_date | 使用する Workers ランタイムのバージョン基準日。UTC基準のため、前日以前を指定すると安全 |
assets.directory | 静的ファイルの置き場(フロントエンド) |
assets.binding | Worker から静的ファイルにアクセスするための名前 |
ai.binding | これが Workers AI の入り口。 Worker の中で env.AI として AI を呼べるようになる |
AI バインディング —
wrangler.jsoncに"ai": { "binding": "AI" }と書くだけで、Worker からenv.AI.run(...)で Workers AI を呼べるようになる。API キーは不要。認証は Cloudflare アカウントに紐づくので、コードに秘密情報を書かなくて済む。
5. フロントエンドの骨組み(5タブ)
Section titled “5. フロントエンドの骨組み(5タブ)”まず入れ物となる UI を作る。5つのタブと、各タブの入力フォーム・出力欄を持つ1ページ。Claude Code に作ってもらう。
public/index.html を作ってください。仕様は以下です。
- ヘッダーに「Cloudflare Workers AI デモ」というタイトル- 「翻訳・要約」「カテゴリ分類」「画像キャプション」「画像生成」「音声書き起こし」の5つのタブ- タブを切り替えると対応するパネルだけが表示される- 各パネルの中身: - 翻訳・要約: テキストエリア + 「翻訳」「要約」ボタン + 出力欄 - カテゴリ分類: 分類カテゴリ(技術トラブル/料金・支払い/使い方の質問/解約・退会)の説明文一覧 + テキストエリア + 「分類」ボタン + 出力欄 - 画像キャプション: 画像ファイルの選択 + プレビュー + 「この画像を説明」ボタン + 出力欄 - 画像生成: プロンプト入力 + 「生成」ボタン + 生成画像の表示 + ダウンロードリンク - 音声書き起こし: 音声ファイルの選択 + 「文字起こし」ボタン + 出力欄- public/style.css と public/app.js を読み込む
style.css も、シンプルで見やすいデザインで作ってください。タブ切り替えとフォーム送信を担当する public/app.js も作る。各タブが対応する API(/api/translate など)に fetch で POST し、返ってきた JSON から必要な値(訳文・分類結果・キャプション・画像・文字起こし結果)を取り出して画面に表示する。
public/app.js を作ってください。
- タブのボタンをクリックしたら、対応するパネルだけ表示する- 翻訳・要約: テキストと mode("translate" か "summarize")を /api/translate に POST し、result を表示- カテゴリ分類: テキストを /api/classify に POST し、result(判定カテゴリ)と scores(各カテゴリのスコア)を表示- 画像キャプション: 選んだ画像を base64 にして /api/caption に POST し、caption を表示- 画像生成: プロンプトを /api/image に POST し、返った base64 画像を img に表示してダウンロードリンクを張る- 音声書き起こし: 選んだ音声を base64 にして /api/transcribe に POST し、text を表示- 画像・音声は FileReader で base64 化する。処理中は「処理中…」と表示する画像や音声をどう送るか — ファイルを
FileReader.readAsDataURL()で読むとdata:image/jpeg;base64,....という文字列になる。この base64 部分を JSON に入れて POST すれば、ファイルをそのまま素直に Worker へ渡せる。アップロード用の特別な仕組みは要らない。
この時点では /api/* の中身がまだ無いので、ボタンを押してもエラーになる。次の章から1つずつ中身を作っていく。
6. Worker の骨組み(ルーター)
Section titled “6. Worker の骨組み(ルーター)”src/index.js を作る。/api/* のパスごとに処理を振り分け、それ以外(HTML/JS/CSS)は静的ファイルとして返す。
src/index.js を作ってください。
- fetch ハンドラで URL のパスを見て振り分ける- /api/translate /api/classify /api/caption /api/image /api/transcribe をそれぞれ別の関数で処理(中身は後で実装、今は空でよい)- /api/ で始まるそれ以外は 404 を JSON で返す- それ以外のパスは env.ASSETS.fetch(request) で静的ファイルを返す- JSON を返すヘルパ関数 json(data, status) を用意する- 使うモデルIDを定数にまとめておく: - テキスト: @cf/meta/llama-3.1-8b-instruct-fp8 - 埋め込み: @cf/pfnet/plamo-embedding-1b - 画像理解: @cf/meta/llama-4-scout-17b-16e-instruct - 画像生成: @cf/black-forest-labs/flux-1-schnell - 音声: @cf/openai/whisper-large-v3-turbo骨組みの一例。
const MODELS = { text: "@cf/meta/llama-3.1-8b-instruct-fp8", embedding: "@cf/pfnet/plamo-embedding-1b", vision: "@cf/meta/llama-4-scout-17b-16e-instruct", image: "@cf/black-forest-labs/flux-1-schnell", speech: "@cf/openai/whisper-large-v3-turbo",};
function json(data, status = 200) { return new Response(JSON.stringify(data), { status, headers: { "content-type": "application/json; charset=utf-8" }, });}
export default { async fetch(request, env) { const url = new URL(request.url); if (url.pathname === "/api/translate") return handleTranslate(request, env); if (url.pathname === "/api/classify") return handleClassify(request, env); if (url.pathname === "/api/caption") return handleCaption(request, env); if (url.pathname === "/api/image") return handleImage(request, env); if (url.pathname === "/api/transcribe") return handleTranscribe(request, env); if (url.pathname.startsWith("/api/")) return json({ error: "Not found" }, 404); // /api/ 以外は静的ファイル(Static Assets)に任せる return env.ASSETS.fetch(request); },};Static Assets と Worker の共存 — Workers Static Assets は「マッチする静的ファイルがあればそれを配信し、無ければ Worker のコードを動かす」という動きをする。
/や/app.jsはファイルが配信され、/api/translateはファイルが無いので Worker が処理する。1つのプロジェクトでフロントとバックエンドが同居できる。
この骨組みができたら、まず一度 Wrangler でデプロイして公開 URL を用意する。本記事では タブを1つ実装するたびにデプロイして、公開サイトでそのタブの動作を確認する 流れで進める。
npx wrangler deploy完了すると公開 URL が表示される。
https://workers-ai-demo.〇〇.workers.devこの URL を開くと、5つのタブを持つ UI が表示される。ただし /api/* の中身がまだ無いので、ボタンを押すとエラーになる。次の章から1つずつ中身を実装し、そのたびにデプロイして確認していく。
手元で素早く試したいときは
npx wrangler devでローカルサーバー(http://localhost:8787)も使える。ただし Workers AI の呼び出しはローカル実行でも Cloudflare 上で動くため、無料枠の Neuron を消費する点は同じ。本記事では公開サイトでの確認に統一する。
7. デモ1: 翻訳・要約(Llama 8B)
Section titled “7. デモ1: 翻訳・要約(Llama 8B)”最初のデモ。テキストを受け取り、Llama 3.1 8B に翻訳または要約させる。messages の システムプロンプト を切り替えるだけで、同じモデルを翻訳にも要約にも使える。
このデモで使うモデル:Llama 3.1 8B(@cf/meta/llama-3.1-8b-instruct-fp8)
| 項目 | 内容 |
|---|---|
| 提供・種類 | Meta / 軽量な大規模言語モデル(80億パラメータ) |
| 得意なこと | 翻訳・要約・分類・短いチャットなど、テキスト→テキスト全般 |
| 品質の目安 | 旧 Claude 3 Haiku と同等〜やや下、GPT-3.5 と同等〜やや上。最新の Haiku 4.5 には及ばない |
| 日本語 | 素の 8B は英語ベースで日本語はやや弱め。重い日本語処理は 70B 系の方が安定する |
| コスト目安 | 短文の翻訳・要約で約2〜5 Neurons(無料枠で1日およそ2,000〜4,000回)。文章が長いほど増える |
src/index.js の handleTranslate を実装してください。
- リクエストボディの JSON から text と mode を取り出す- text が空なら 400 でエラーを返す- mode が "summarize" なら「日本語で3行以内に要約」するシステムプロンプトにする- 翻訳のときは、テキストに日本語が含まれていれば英語へ、なければ日本語へ訳す。向きはコード側で判定し、モデルには「◯語に翻訳する」という1つの指示だけ渡す- env.AI.run(MODELS.text, { messages: [...] }) を呼ぶ- 結果の response を { result } として返す- エラーは try/catch で 500 を返す実装の一例。
async function handleTranslate(request, env) { try { const { text, mode } = await request.json(); if (!text || !text.trim()) return json({ error: "テキストが空です" }, 400);
// 翻訳の向きはコード側で決める。日本語が含まれていれば英語へ、なければ日本語へ const hasJapanese = /[-ヿ一-龯]/.test(text); const target = hasJapanese ? "英語" : "日本語";
const system = mode === "summarize" ? "あなたは優秀な要約者です。入力文を日本語で簡潔に3行以内に要約してください。要約だけを出力すること。" : `あなたは優秀な翻訳者です。次の文章を${target}に翻訳してください。訳文だけを出力すること。`;
const res = await env.AI.run(MODELS.text, { messages: [ { role: "system", content: system }, { role: "user", content: text }, ], }); return json({ result: res.response ?? "" }); } catch (e) { return json({ error: String(e) }, 500); }}実装できたらデプロイする。
npx wrangler deploy公開サイトの「翻訳・要約」タブを開き、テキストを入れて「翻訳」を押す。日本語なら英語に、英語なら日本語に訳されれば成功。「要約」を押せば長文が数行に圧縮される。
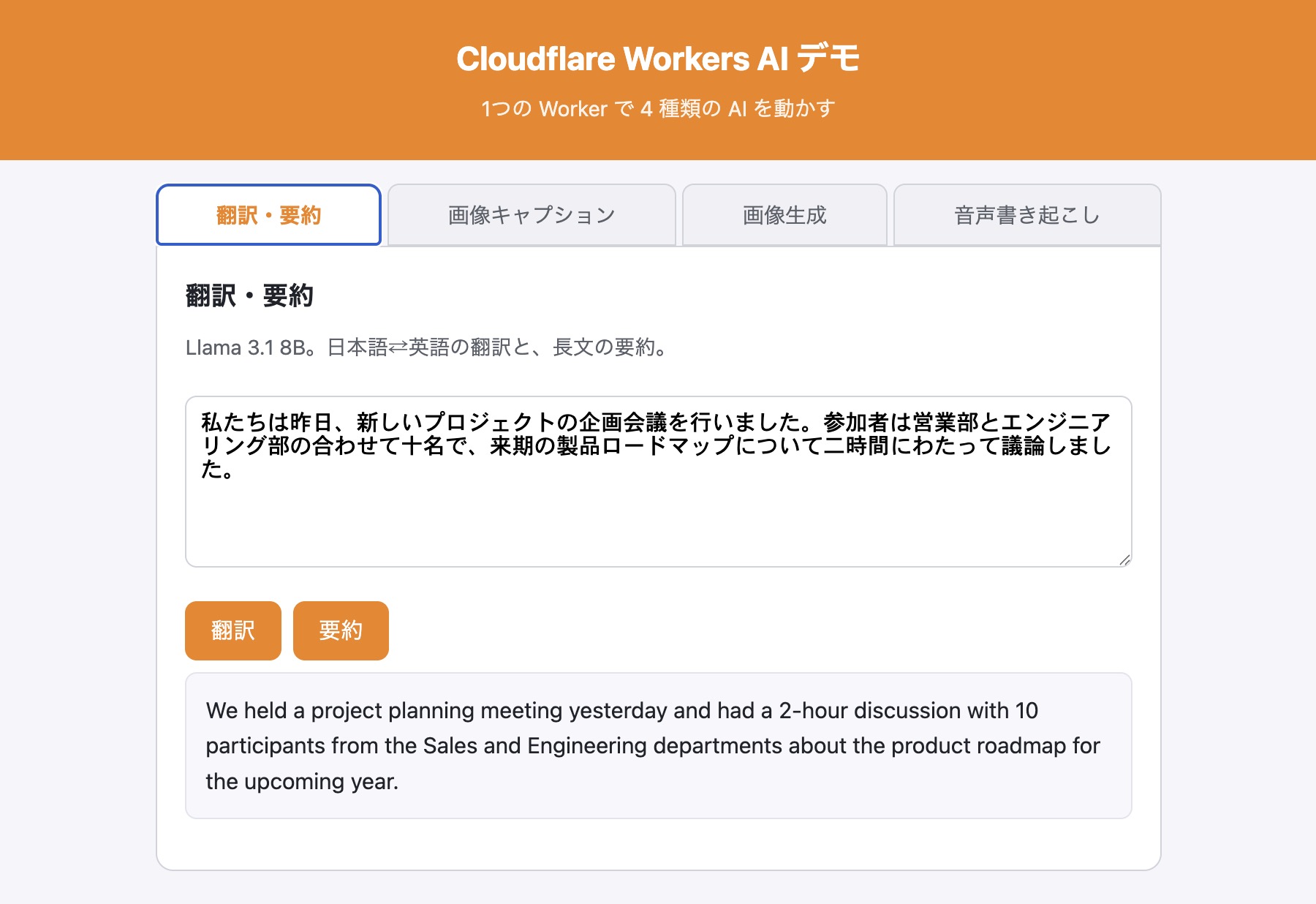
チャット系モデルの基本形 — Llama のようなテキスト生成モデルは
messagesの配列で会話を渡す。role: "system"で「どう振る舞うか」を指示し、role: "user"で入力を渡す。返り値のresponseに生成テキストが入る。翻訳・要約・分類・チャットなど、テキスト→テキストの用途はすべてこの形。
軽量モデルには「判断」を任せすぎない — 当初は「日本語なら英語に、そうでなければ日本語に」とモデル自身に翻訳の向きを判断させていたが、8B のような軽量モデルだと時々それを外し、同じ言語で言い換えてしまうことがあった。翻訳の向きをコード側(
hasJapanese)で決め、モデルには「英語に翻訳して」と1つの仕事だけ渡すと安定する。軽量モデルを使うときは「判断はコードで、生成だけモデルに」が定石。
8. デモ2: カテゴリ分類(PLaMo Embedding)
Section titled “8. デモ2: カテゴリ分類(PLaMo Embedding)”問い合わせ文を「技術トラブル/料金・支払い/使い方の質問/解約・退会」に振り分ける。ここまでの生成系モデルと違い、埋め込みモデルを使う。埋め込みは文章を意味のベクトル(数値の並び)に変換するモデルで、文章そのものは生成しない。代わりに「2つの文の意味がどれだけ近いか」をコサイン類似度で測れる。話題で分ける分類は、埋め込みが最も得意とするところ。学習データを用意せず、カテゴリを説明文で与えるだけで分類できるので、こうした手法は「ゼロショット分類」と呼ばれる。
これを使った分類の流れはこう:
- 入力文と、各カテゴリの説明文を埋め込む
- 入力文ベクトルと各カテゴリ説明文ベクトルのコサイン類似度を計算する
- 一番近いカテゴリに分類する
学習もファインチューニングも不要(ゼロショット)。カテゴリを増やしたいときは説明文を足すだけ。
このデモで使うモデル:PLaMo-Embedding-1B(@cf/pfnet/plamo-embedding-1b)
| 項目 | 内容 |
|---|---|
| 提供・種類 | Preferred Networks / 日本語特化の埋め込みモデル(2048次元) |
| 得意なこと | 日本語の意味的な検索・分類・クラスタリング。文章→ベクトル変換 |
| 特徴 | 文章は生成しない。「意味の近さ」を測る部品。多言語や長文が必要なら BGE-M3(@cf/baai/bge-m3)にモデルIDを差し替えるだけで乗り換えられる |
| コスト目安 | 1回あたり約1 Neuron 未満。埋め込みは生成系よりずっと軽い |
ラベルは単語より「説明文」にする — カテゴリを
技術トラブルのような単語ではなく、この文章は…技術的な不具合の報告だ。のような説明文にして埋め込むと、分類の精度が上がる。埋め込みモデルは文どうしの類似度を学習しているため、ラベル側も文の形にするほうが入力文と比べやすい。
実装は、Worker に分類 API を作る。フロントの「カテゴリ分類」タブは5章の骨組みで作成済み。
src/index.js に handleClassify を実装し、/api/classify ルートを追加してください。
- カテゴリ定数 CATEGORIES を用意する。各カテゴリは name(表示名)と proto(説明文)を持つ: - 技術トラブル: この文章はログインできない、エラーが出る、動かないといった技術的な不具合の報告だ。 - 料金・支払い: この文章は料金や請求金額、支払い方法に関する問い合わせだ。 - 使い方の質問: この文章は機能の使い方や操作方法がわからないという質問だ。 - 解約・退会: この文章は解約や退会、サービスの利用停止をしたいという依頼だ。- リクエストの JSON から text を取り出す。空なら 400- [入力文, ...各カテゴリの説明文] を env.AI.run(MODELS.embedding, { text: [...] }) で一括埋め込み- 返り値 res.data の先頭が入力文ベクトル、2番目以降が各カテゴリのベクトル- 入力文ベクトルと各カテゴリベクトルのコサイン類似度を計算し、高い順に並べる- { result: 最上位カテゴリ名, scores: [{name, score}...] } を返す- MODELS に embedding: "@cf/pfnet/plamo-embedding-1b" を追加する実装の一例。
const CATEGORIES = [ { name: "技術トラブル", proto: "この文章はログインできない、エラーが出る、動かないといった技術的な不具合の報告だ。" }, { name: "料金・支払い", proto: "この文章は料金や請求金額、支払い方法に関する問い合わせだ。" }, { name: "使い方の質問", proto: "この文章は機能の使い方や操作方法がわからないという質問だ。" }, { name: "解約・退会", proto: "この文章は解約や退会、サービスの利用停止をしたいという依頼だ。" },];
async function handleClassify(request, env) { try { const { text } = await request.json(); if (!text || !text.trim()) return json({ error: "テキストが空です" }, 400);
// 入力文と各カテゴリの説明文をまとめて埋め込む(1回のバッチ呼び出し) const inputs = [text, ...CATEGORIES.map((c) => c.proto)]; const res = await env.AI.run(MODELS.embedding, { text: inputs }); const vecs = res.data; // [入力, カテゴリ1, カテゴリ2, ...] const inputVec = vecs[0];
const scores = CATEGORIES.map((c, i) => ({ name: c.name, score: cosineSimilarity(inputVec, vecs[i + 1]), })).sort((a, b) => b.score - a.score);
return json({ result: scores[0].name, scores }); } catch (e) { return json({ error: String(e) }, 500); }}
// コサイン類似度: 2つのベクトルの向きの近さを -1〜1 で返す(1に近いほど意味が近い)function cosineSimilarity(a, b) { let dot = 0, na = 0, nb = 0; for (let i = 0; i < a.length; i++) { dot += a[i] * b[i]; na += a[i] * a[i]; nb += b[i] * b[i]; } return dot / (Math.sqrt(na) * Math.sqrt(nb));}実装できたらデプロイする。
npx wrangler deploy公開サイトの「カテゴリ分類」タブを開き、問い合わせ文を入れて「分類」を押す。「ログインするとエラーが出ます」→技術トラブル、「先月分が二重に請求されている」→料金・支払い、「画像の変更方法がわからない」→使い方の質問、「解約したい」→解約・退会、のように振り分けられ、各カテゴリのスコアも表示される。
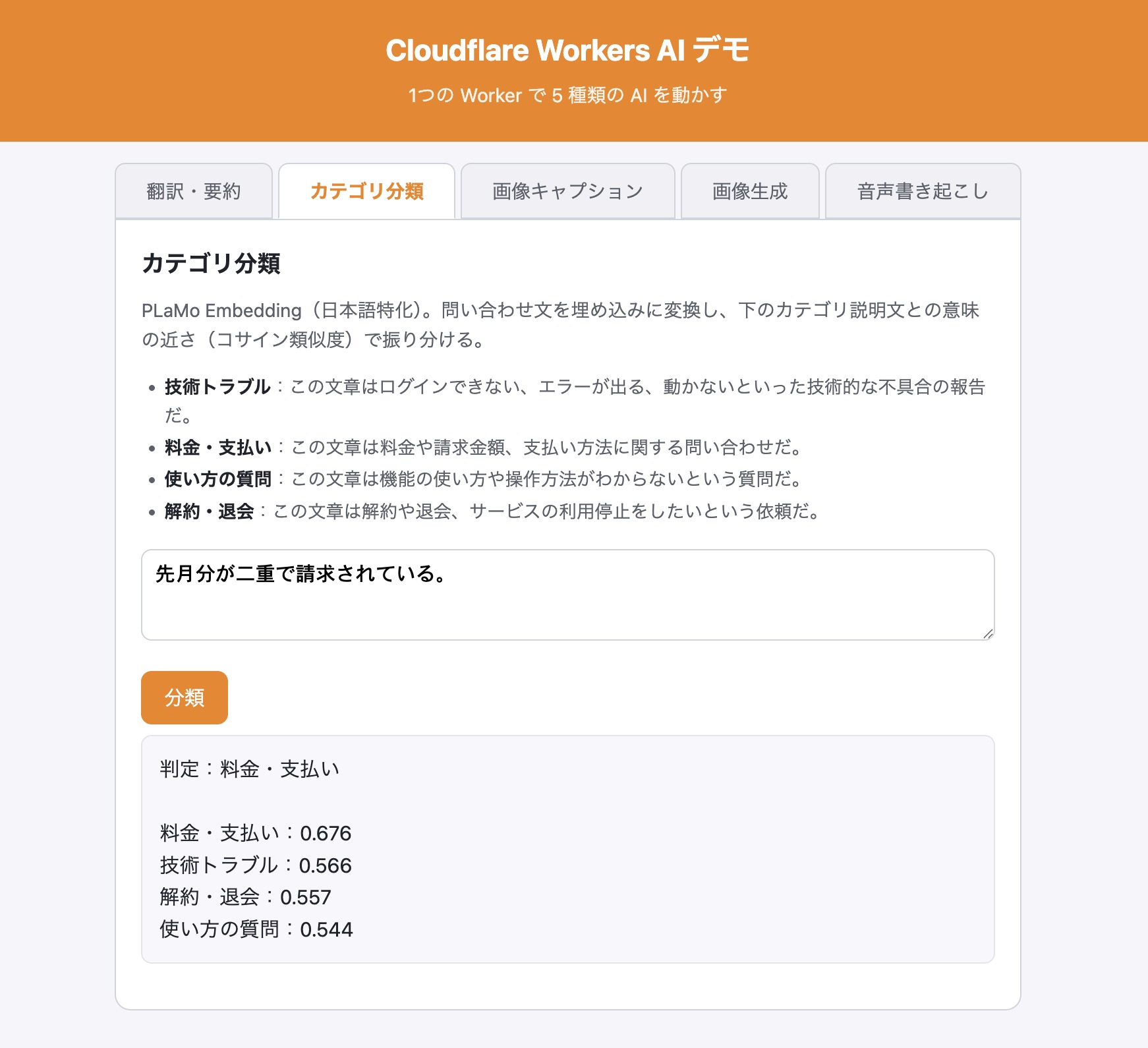
埋め込み分類は「話題で分ける」のが得意 — 問い合わせの振り分けのように、カテゴリが話題として明確に分かれている分類は埋め込みの得意分野で、安定して当たる。一方、ポジティブ/ネガティブのような感情の分類では、賛否が混ざった微妙な文は揺れやすい(感情のニュアンスは話題ほどベクトルの距離に出にくいため)。カテゴリを変えたいときは、各カテゴリの説明文(プロトタイプ)を差し替えるだけでよい。
9. デモ3: 画像キャプション生成(Llama 4 Scout)
Section titled “9. デモ3: 画像キャプション生成(Llama 4 Scout)”アップロードされた画像に何が写っているかを説明させる。Llama 4 Scout は マルチモーダル(テキストと画像を同時に理解)なので、画像とプロンプトを一緒に渡せる。
このデモで使うモデル:Llama 4 Scout 17B(@cf/meta/llama-4-scout-17b-16e-instruct)
| 項目 | 内容 |
|---|---|
| 提供・種類 | Meta / ネイティブマルチモーダル(テキスト+画像)の MoE モデル |
| 得意なこと | 画像の説明・分類、画像を見ながらの質問応答 |
| 特徴 | MoE(複数の専門家モデルを使い分ける方式)で 17B ながら 70B 級の効率。画像とテキストを同じモデルで扱うので、画像理解用に別モデルを用意しなくてよい |
| コスト目安 | 1枚あたり約14 Neurons(小さめの画像の場合)。画像が大きい・キャプションが長いほど増える |
src/index.js の handleCaption を実装してください。
- リクエストボディの JSON から image(base64)と prompt を取り出す- image が無ければ 400- data URI 形式("data:image/...;base64,...")で来ても base64 本体だけ取り出すようにする- prompt が無ければ「この画像に何が写っているか日本語で簡潔に説明してください」をデフォルトにする- env.AI.run(MODELS.vision, { messages: [...] }) を呼ぶ。messages の content は [{ type: "text", text: 質問 }, { type: "image_url", image_url: { url: "data:image/jpeg;base64," + b64 }}]- 結果の response を { caption } として返すポイントは content を 配列 にして、テキストと画像を並べて渡すところ。
実装の一例。
async function handleCaption(request, env) { try { const { image, prompt } = await request.json(); if (!image) return json({ error: "画像がありません" }, 400);
// "data:image/...;base64,XXXX" なら XXXX だけ取り出す const comma = image.indexOf(","); const b64 = image.startsWith("data:") && comma !== -1 ? image.slice(comma + 1) : image; const question = prompt?.trim() || "この画像に何が写っているか日本語で簡潔に説明してください。";
const res = await env.AI.run(MODELS.vision, { messages: [ { role: "user", content: [ { type: "text", text: question }, { type: "image_url", image_url: { url: `data:image/jpeg;base64,${b64}` } }, ], }, ], }); return json({ caption: res.response ?? "" }); } catch (e) { return json({ error: String(e) }, 500); }}実装できたらデプロイする。
npx wrangler deploy公開サイトの「画像キャプション」タブで、手元の写真を選んで「この画像を説明」を押す。たとえばブドウを両手に持った写真をアップすると、次のような説明が返ってくる。
{"caption":"この画像には、黒いブドウの房を持った人の手が写っています。"}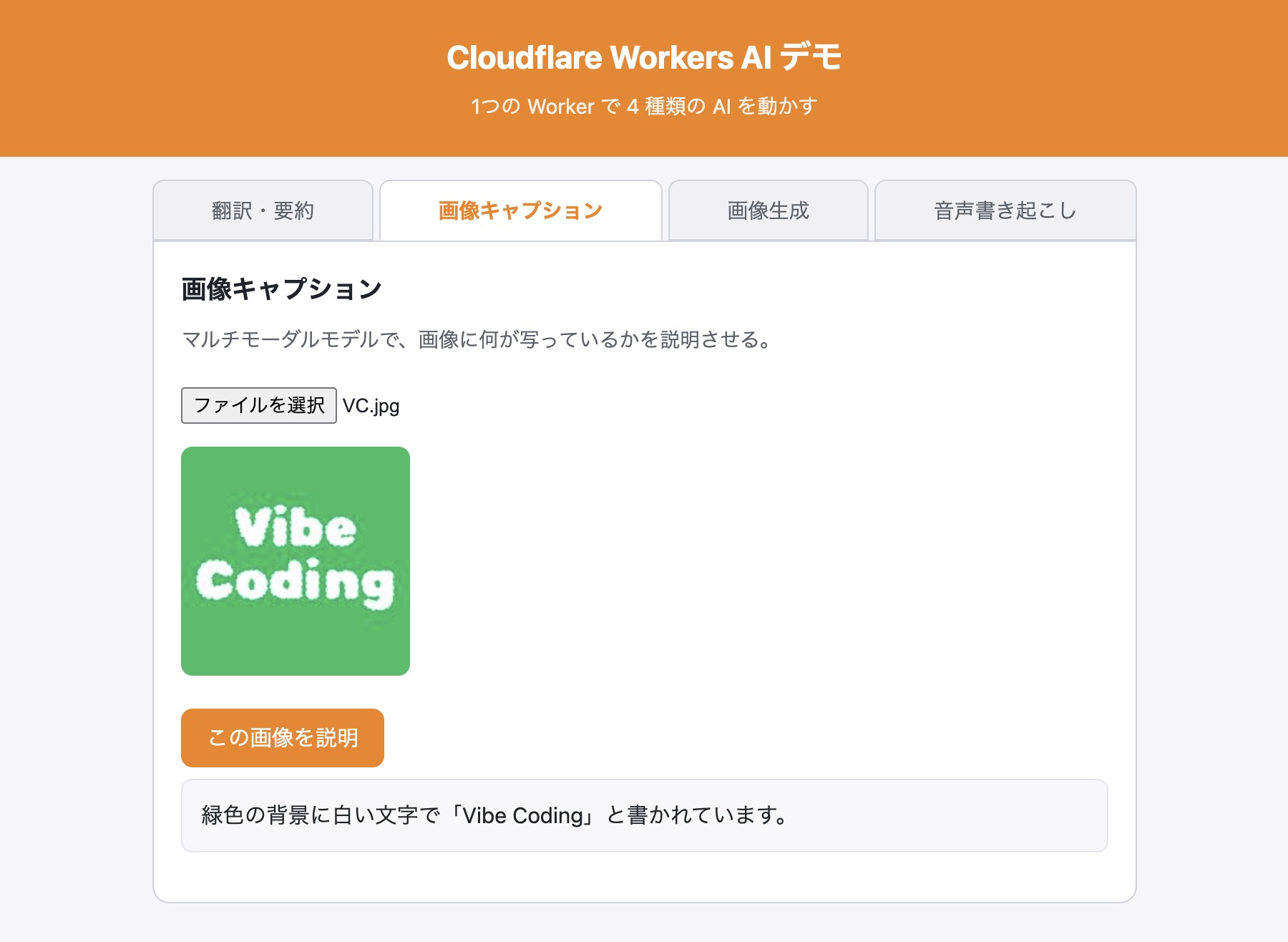
マルチモーダルモデルへの画像の渡し方 — Llama 4 Scout は OpenAI 互換の形式を受け付ける。
contentを配列にして、type: "text"のテキストとtype: "image_url"の画像を並べる。画像はdata:image/jpeg;base64,....という データ URI の文字列で渡せばよい。
10. デモ4: 画像生成(FLUX.1 [schnell])
Section titled “10. デモ4: 画像生成(FLUX.1 [schnell])”テキストから画像を生成する。FLUX.1 [schnell] は速くて軽く、無料枠でも数百枚生成できる。
このデモで使うモデル:FLUX.1 [schnell](@cf/black-forest-labs/flux-1-schnell)
| 項目 | 内容 |
|---|---|
| 提供・種類 | Black Forest Labs / テキストから画像を生成するモデル |
| 特徴 | 少ないステップ(既定4)で速く生成。schnell はドイツ語で「速い」の意味 |
| コスト目安 | 1024×1024・4ステップで約170 Neurons(無料枠で1日およそ58枚)。テキスト処理の数十倍で、無料枠を一気に使う |
| 使い分け | schnell は速さ重視の軽量版で、より高品質な FLUX.1 [dev] 等はさらに重い。手軽に試す用途向き |
src/index.js の handleImage を実装してください。
- リクエストボディの JSON から prompt を取り出す。空なら 400- env.AI.run(MODELS.image, { prompt, steps }) を呼ぶ。steps は 1〜8 に収める(無ければ 4)- 返り値の image(base64 のJPEG)をそのまま { image } として返す実装の一例。
async function handleImage(request, env) { try { const { prompt, steps } = await request.json(); if (!prompt || !prompt.trim()) return json({ error: "プロンプトが空です" }, 400);
const res = await env.AI.run(MODELS.image, { prompt, steps: Math.min(Math.max(Number(steps) || 4, 1), 8), }); // res.image は base64 形式の JPEG return json({ image: res.image }); } catch (e) { return json({ error: String(e) }, 500); }}フロント側(app.js)では、返ってきた base64 を data:image/jpeg;base64,... の形にして <img> の src に入れれば表示できる。同じ文字列をダウンロードリンクの href に入れれば、そのまま保存もできる。
const { image } = await postJSON("/api/image", { prompt });const dataUri = "data:image/jpeg;base64," + image;imageOutput.src = dataUri; // 画面に表示imageDownload.href = dataUri; // ダウンロードリンク画像の保存に R2 は要らない — 生成画像をサーバーに保存して URL で配る使い方もできる(その場合は R2 ストレージを使う)。だが「生成してその場でダウンロードできればよい」なら、base64 をブラウザに返して
<a download>で保存させるだけで完結する。今回はこの軽い方式を採る。
実装できたらデプロイする。
npx wrangler deploy公開サイトの「画像生成」タブで a cute robot reading a book in a cozy library, warm light(暖かい光の図書館で本を読むかわいいロボット)のように入力すると、数秒で 1024×1024 の画像が生成され、ダウンロードリンクから保存できる。
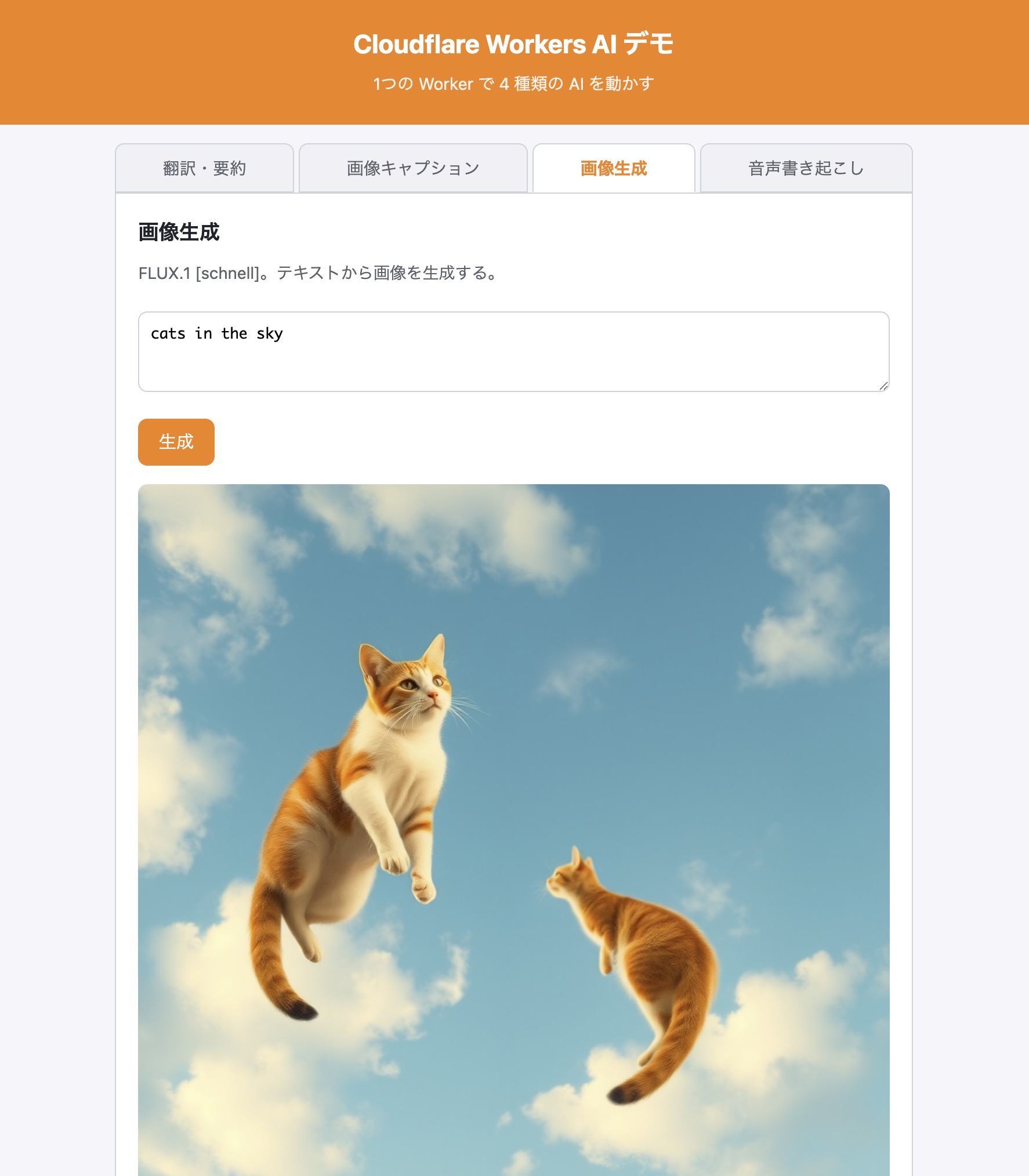
プロンプトは英語のほうが安定して効く。日本語で書いても通じるが、思い通りの絵にしたいときは英語で具体的に指定するとよい。
11. デモ5: 音声書き起こし(Whisper)
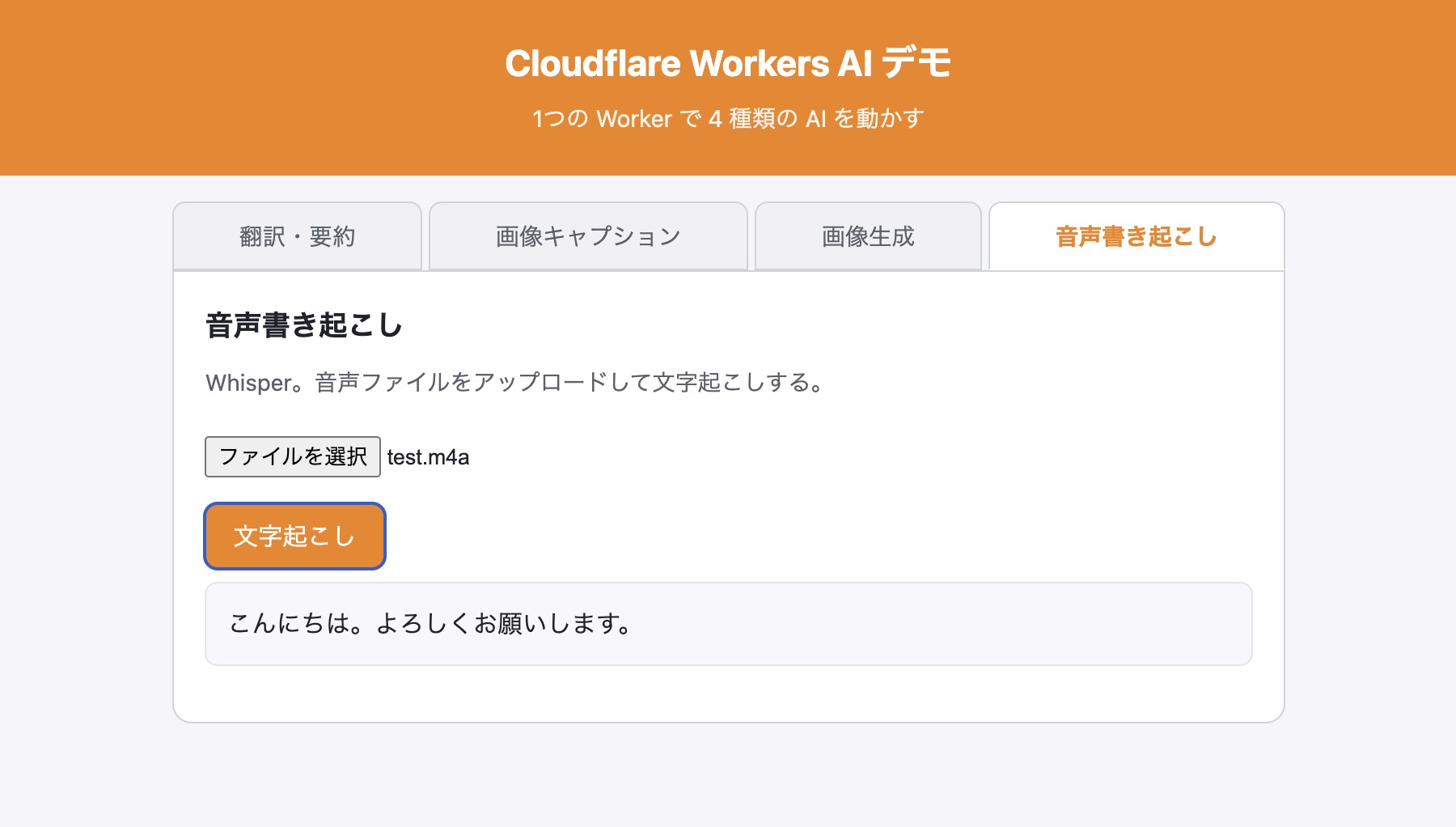
Section titled “11. デモ5: 音声書き起こし(Whisper)”最後は音声ファイルを文字起こしする。ライブ録音の仕組みは作らず、音声ファイルをアップロードする だけのシンプルな形にする。
このデモで使うモデル:Whisper large v3 turbo(@cf/openai/whisper-large-v3-turbo)
| 項目 | 内容 |
|---|---|
| 提供・種類 | OpenAI / 音声認識(音声→テキスト)モデル |
| 得意なこと | 多言語の文字起こし。task: "translate" を指定すると英語への翻訳もできる |
| 特徴 | turbo 版は通常の large v3 より高速。言語は自動判定される |
| コスト目安 | 音声1分あたり約47 Neurons(無料枠で1日およそ210分=3.5時間) |
src/index.js の handleTranscribe を実装してください。
- リクエストボディの JSON から audio(base64)を取り出す。無ければ 400- data URI 形式なら base64 本体だけ取り出す- env.AI.run(MODELS.speech, { audio: b64 }) を呼ぶ- 結果の text(無ければ transcription_info.text)を { text } として返す実装の一例。
async function handleTranscribe(request, env) { try { const { audio } = await request.json(); if (!audio) return json({ error: "音声がありません" }, 400);
const comma = audio.indexOf(","); const b64 = audio.startsWith("data:") && comma !== -1 ? audio.slice(comma + 1) : audio;
const res = await env.AI.run(MODELS.speech, { audio: b64 }); const text = res.text ?? res.transcription_info?.text ?? ""; return json({ text }); } catch (e) { return json({ error: String(e) }, 500); }}実装できたらデプロイする。
npx wrangler deploy公開サイトの「音声書き起こし」タブで、手元の音声ファイル(.m4a や .mp3 など)を選んで「文字起こし」を押すと、テキストが返ってくる。これで5つのデモがすべて公開サイト上で動く。
Whisper の入力 — 音声データは base64 文字列を
audioキーで渡す。.m4a.mp3.wavなど一般的な形式が使える。言語は自動判定されるが、はっきりした音声ほど精度が上がる。日本語の音声なら、入力{ audio, language: "ja" }のように言語を明示すると安定する。
手元に音声ファイルがなければ、Mac 標準の QuickTime Player(追加インストール不要)で手軽に録音できる。ファイル → 新規オーディオ収録 を選び、収録を開始 ボタンで話し、終わったら 収録を停止 を押す。あとは ファイル → 保存 で名前を付けて保存すれば .m4a 形式で書き出されるので、それをそのまま「音声書き起こし」タブにアップロードすればよい。なお品質を 最高 にすると .m4a ではなく非圧縮の AIFF になるため、.m4a が欲しいときは品質を既定の 高 のままにしておく。
12. モデル選択の指針
Section titled “12. モデル選択の指針”Workers AI には50以上のモデルがある。今回使った5つ以外にも選択肢は多い。品質と用途の目安:
| やりたいこと | 目安 |
|---|---|
| 翻訳・要約・分類・短いチャット | Llama 8B で十分。速くて安い |
| しっかりした文章生成・複雑な指示 | Llama 70B 系。8B より賢いが Neuron を多く使う |
| 画像の理解(説明・分類) | Llama 4 Scout などマルチモーダルモデル |
| 画像生成(手軽に大量) | FLUX.1 [schnell]。速くて無料枠に優しい |
| 文字起こし | Whisper |
「Workers AI の Llama は Claude や GPT でいうとどのへんか」を大まかに対応させると、こうなる。
| Workers AI のモデル | だいたいの相当 |
|---|---|
| Llama 3.2 1B / 3B | とても軽量。Claude/GPT に該当なし |
| Llama 3.1 8B(本記事で使用) | 旧 Claude 3 Haiku 同等〜やや下、GPT-3.5 同等〜やや上 |
| Llama 3.3 70B | GPT-4o-mini 〜 GPT-4o の間、Claude Haiku 4.5 と同等〜やや上 |
| Llama 4 Scout 17B(本記事で使用) | MoE で 70B 級の効率。マルチモーダルは Haiku 4.5 に近い領域 |
Workers AI のモデルは、Claude や GPT の 上位モデル(Sonnet以降、GPT-4以降)には品質で遠く及ばない。「賢さ」で勝負する用途は Claude API などに任せ、Workers AI は 「気軽・安い・エッジで速い」 が効く用途で使うのが現実的な棲み分け。重い処理は Claude、軽い常時処理は Workers AI、と役割分担で組み合わせるとよい。
13. 公開後の注意と後始末
Section titled “13. 公開後の注意と後始末”このデモは「誰でも使えるページ」なので、API(/api/*)も誰でも叩ける。AI の呼び出しは自分のアカウントの Neuron を消費するため、ハンズオンが終わったら公開したまま放置せず、止めておくのがおすすめ。
何が守れて何が守れないかを整理しておく。
- 隠せているもの: AI を呼ぶのは Worker(サーバー側)なので、アカウントや binding といった「鍵」はブラウザに出ていない。外から見えるのは「入口(API のURL)」と「結果」だけ
- 隠せないもの: ユーザーが自由に入力するデモである以上、ブラウザが叩ける入口は必ず必要で、これを完全に隠すことはできない。
Originチェックやレート制限で「自分のページからの利用」に近づけることはできるが、絶対ではない。きちんと守るなら Cloudflare Access や Basic認証 で認証をかける
触り終えたら、次のどちらかをしておくとよい。
(a) Worker ごと削除する(いちばん確実)
npx wrangler deleteURL ごと消える。また使いたくなったら npx wrangler deploy で再公開すればよい。
(b) API を一時的に無効化する(URL は残しておきたいとき)
src/index.js の先頭にスイッチを置き、/api/* を止めておく方法もある。Claude Code にこう頼む。
src/index.js に API を一時停止できるスイッチを追加してください。ファイルの先頭に const API_ENABLED = false; を置き、/api/ で始まるリクエストは API_ENABLED が false のときは503 エラー(JSON)を返すようにしてください。true に戻してデプロイし直せば元どおり動くようにします。たとえば次のように書き換わる。
const API_ENABLED = false; // 使うときだけ true にしてデプロイ
export default { async fetch(request, env) { const url = new URL(request.url); if (url.pathname.startsWith("/api/") && !API_ENABLED) { return json({ error: "現在停止中です" }, 503); } // …以下、これまでの振り分け… },};使いたいときだけ true に戻して npx wrangler deploy し直す。無効化中はボタンを押してもエラーになるだけで、AI は呼ばれない=Neuron も消費されない。
無料枠の消費状況は Cloudflare ダッシュボードの Workers & Pages → AI で確認できる。
2026-06-12 (last updated: 2026-06-18) ![]() タツヲ (yto)
タツヲ (yto)